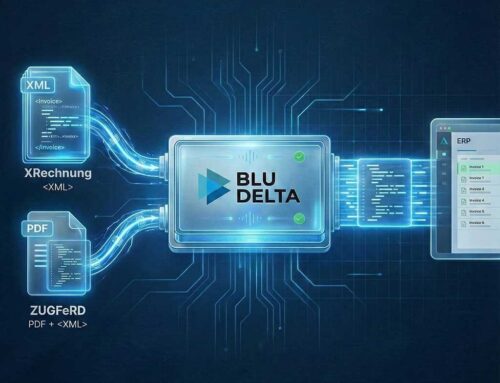
Document capturing refers to the process of converting unstructured data into a normalized, structured format. Essentially, it provides a summary of a document with a pre-defined structured and uniform text output, ready for subsequent company processes and workflows.

At first glance, this seems like an ideal task for models like ChatGPT or other pretrained LLMs. (For a comprehensive overview of LLMs, including details about inference, training, applications, and challenges, see following research paper). Many readers might have asked ChatGPT to summarize a document, but how many have considered integrating an LLM into a professional, automated back-office process? Especially in areas where consistent and trustworthy output is paramount?
Let's delve deeper into the use of LLMs for document capturing in back-office processes and explore ways to ensure their reliability.
LLMs are Designed for Human-like Texts
LLMs are engineered to understand human-like language input and produce human-like text outputs. For document capturing, this implies that before deploying LLMs, we must preprocess our images or PDF-like files, converting them into text. We cannot avoid the so-called OCR (see also our article: "What is OCR?") and the associated source of errors in poor image or document quality.
What About Layout?
Humans don't typically communicate information solely through prose. We use paragraphs, tables, alignments, and more to convey information efficiently. The layout itself carries meaning. By default, LLMs don't process 2-dimensional information. They handle plain text, line by line. Simply using OCR to convert text and feeding it into an LLM might not suffice. Ideally, we should first segment the content into semantic chunks or regions to provide meaningful input for the LLM.
Size Matters
LLMs have limitations on the volume of input and output text they can handle. Current LLMs can process only up to a certain number of tokens. For extensive documents, a strategy is needed to break the content into coherent segments.
LLMs Process Public Domain Documents Out-of-the-box
The efficacy of an AI often hinges on data, and LLMs are no exception. They are trained on publicly available sources like websites, Wikipedia, research papers, and books. For document capturing, the context is crucial. If a document's content and surrounding knowledge are publicly accessible, an LLM can extract information instantly, with no additional setup required.
Does It Always Work?
Consider the invoice, arguably the most common document globally. While certain fields on invoices are standardized (especially in Europe), they might contain company-specific information not available publicly, making it challenging for an LLM to capture. This includes details like order ID formats or logistics company tour numbers. It's vital to distinguish between public information and domain-specific knowledge. If a use case demands domain-specific or company context information, model fine-tuning or prompt engineering becomes necessary.
Addressing Hallucination
In AI, "hallucination" refers to instances when an LLM generates incorrect information. With document capturing, we transform unstructured data into structured formats. The beauty of structured data is its measurability. The reliability of an LLM extracting data can be statistically validated. Using a comprehensive benchmark system, data capturing solution providers can attest to the accuracy up to a specific error rate.
Conclusion
While LLMs present substantial advantages in data capturing, it's crucial to recognize their limitations. Merging the strengths of LLMs with domain-specific expertise and validation mechanisms ensures the accuracy and reliability of captured data. One significant benefit in document capturing also with LLMs is the ability to automatically benchmark outputs. Employing a robust and repeatable benchmark system, like the one BLU DELTA team uses, guarantees trustworthy results.
BLU DELTA is a product for the automated capture of financial documents. Partners, but also finance departments, accounts payable accountants and tax advisors of our customers can use BLU DELTA to immediately relieve their employees of the time-consuming and mostly manual capture of documents by using BLU DELTA AI and Cloud.
BLU DELTA is an artificial intelligence from Blumatix Intelligence GmbH.

Author: Christian Weiler is the former General Manager of a global IT company based in Seattle/US. Since 2016, Christian Weiler has been increasingly active in the field of artificial intelligence in a variety of roles and has been part of the management team of Blumatix Intelligence GmbH since 2018.
Contact: c.weiler@blumatix.com